

现有的SDN解决方案将控制平面与转发平面分离,并为我们提供了控制平面的可编程能力。而事实上,目前通过软件编程实现的控制平面的功能,在传统的高级交换机和路由器上也都能实现,差别是厂商把这些功能固化在了系统/硬件中,这些系统/硬件是封闭的,第三方难以介入进行定制或二次开发。虽然一些高级设备提供了SDK,使得用户能够进行一定程度的定制,但也必须受厂商所制定的规范的限制,能做到的事情十分有限。目前SDN所做的就是打破这些限制,让设备和网络更加的灵活,让用户不被厂商设备绑定,从而拥有无限的可能。
现有的SDN解决方案为用户开放的是控制平面的可编程能力,那转发平面呢?正常情况下,转发设备的数据包解析,转发流程是由设备转发芯片固化的,所以设备在协议的支持方面并不具备扩展能力。并且,厂商开发新的转发芯片以支持新的协议或者扩展协议特性的代价也非常高,需要将以前的硬件重新设计,势必导致更新成本高,时间周期长等一系列问题。所以在一定程度上,这种将设备功能和协议支持与硬件绑定的模式限制了网络的快速发展。
因此,我们可以得出以下结论:新一代的SDN解决方案必须让数据转发平面也具有可编程能力,让软件能够真正定义网络和网络设备。而P4正是为用户提供了这种能力,打破了硬件设备对数据转发平面的限制,让数据包的解析和转发流程也能通过编程控制,使得网络及设备自上而下地、真正地向用户开放。
下面,我们主要从以下几个方面谈谈我对P4这门转发平面的编程语言的理解:P4的架构及特性、交换机结构、P4程序工作流程。
1.P4架构及特性
首先我们谈谈P4的诞生,由Nick教授,博科姆教授等联合发布了一篇论文《P4: Programming Protocol-Independent Packet Processors》,该论文在SDN界引起了极大的反响和关注度。随后,Nick教授等人又发布了《The P4 Language Specification》、《Barefoot白皮书》等文件。目前,P4已经在国外引起了足够的重视,ONF成立了协议无关转发的开源项目(PIF),该项目目前的工作重点就是为P4提供配套的中间表示IR(Intermediate Representation),另外PIF工作的成果将被用来设计下一代的OpenFlow协议。
目前人们提及最多的OpenFlow协议在逐渐的完善演化过程中,表字段和表类型不断的增加。白牌交换机在支持OpenFlow协议的版本更新上,面临着和传统交换设备厂商同样的困境——OpenFlow并不支持弹性地增加匹配域支持,协议新特性的支持所需要的成本大、时间周期长。同时,随着网络中新的协议不断出现,OpenFlow协议也必将变得越来越臃肿,表的扩展也必将变得越来越困难。
P4语言在设计之初,就是为了实现以下三个特性:
(1)协议无关性
网络设备不与任何特定的网络协议绑定,用户可以使用P4语言描述任何网络数据平面协议和数据包处理行为。这一特性通过自定义包解析器、匹配-动作表的匹配流程和流控制程序实现。
(2)目标无关性
用户不需要关心底层硬件的细节就可实现对数据包的处理方式的编程描述。这一特性通过P4前后端编译器实现,前端编译器将P4高级语言程序转换成中间表示IR,后端编译器将IR编译成设备配置,自动配置目标设备。
(3)可重构性
允许用户随时改变包解析和处理的程序 ,并在编译后配置交换机,真正实现现场可重配能力。
为了实现上述特性,P4语言的编译器采用了模块化的设计,各个模块之间的输入输出都采用标准格式的配置文件,如p4c-bm模块的输出作为载入到bmv2模块中的JSON格式配置文件。P4的架构图如图1所示。

图1 P4架构图
2. 交换机结构
在传统交换机中,数据流转化为数据帧之后进行解析,首先检查的是tag,包括有无tag、灵活Q-in-Q、VLAN映射等。VLAN tag的检查和处理在所有厂商的交换机中都是必须的,但随后数据包处理流程就因厂商而异了,不同厂商的芯片设计会产生不同的处理流程,每个处理流程就是一个基础的数据处理单元,一般情况下,交换机的流水线包含6-8个数据处理单元。

图2 传统交换机流水线结构
图2中列出的是几个比较常见的数据帧处理单元,如二层转发、ACL转发等。流水线上每个基础数据处理单元处理数据的过程,就是根据数据帧解析后的包头信息,重复查表、匹配并执行对应的交换机指令的过程。
P4交换机中也有流水线(pipeline)的概念,一条流水线表示一组完整的数据处理流程,这一概念和传统交换机中的的流水线是相似的。如图3所示,在P4交换机中一条流水线可以包含以下组件:解析器/逆解析器、匹配-动作表、元数据总线。其中除了元数据总线,其他组件都是非必须的。
解析器(parser):将分组数据转化成元数据。
逆解析器(Deparser):将元数据转化成序列化的分组数据。
匹配动作表(match-action table):操作元数据。
元数据(metadata):在流水线内存储数据信息。
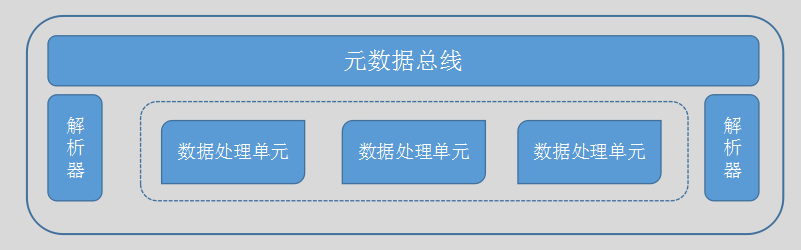
图3 P4交换机流水线结构
P4交换机中将流水线处理数据的过程进行抽象和重定义,数据处理单元对数据的处理抽象成匹配和执行匹配-动作表的过程,包头的解析抽象成P4中的解析器,数据处理流程抽象成流控制。P4中基础数据处理单元是不记录数据的,所以就需要引入一个元数据总线,用来存储一条流水线处理过程中需要记录的数据。P4交换机的专用物理芯片Tofino,最高支持12个数据处理单元,可以覆盖传统交换机的所有功能。
有了以上的知识储备,就可以很轻松的刻画出P4交换机的结构。如图4所示,P4交换机中含有两条流水线——入口流水线和出口流水线;同时还有一些数据流管理功能,例如:拥塞控制,队列控制,流量复制等。
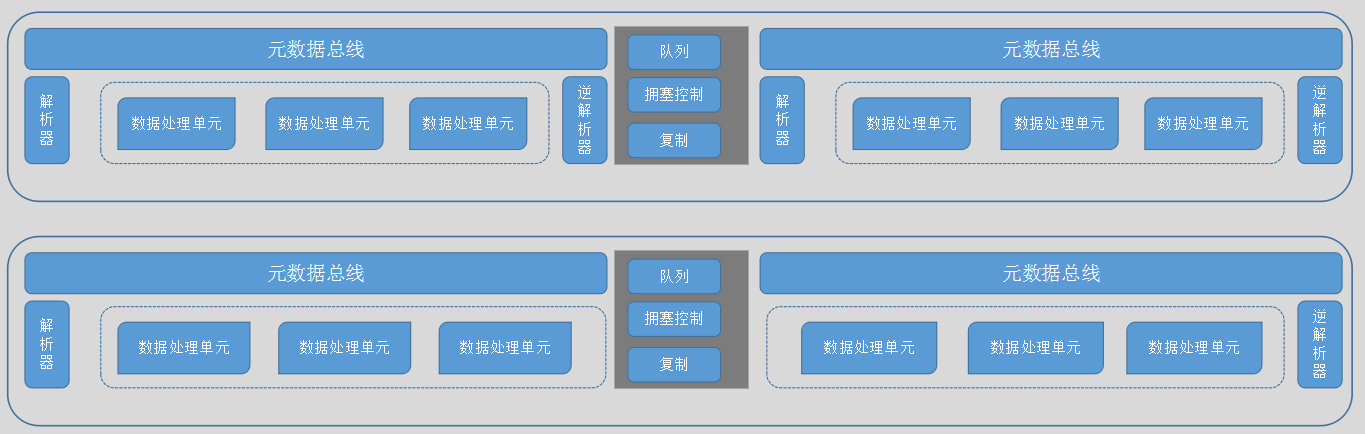
图4 P4交换结构
对比图2 图3和图4,我们不难看出P4交换机结构与传统的交换机并没有多少差别,而且在芯片的设计上也仅仅是增加了可以自定义基础数据处理单元和转发流程的功能,其他设计与传统交换机芯片无异,这也使得P4交换机能够在为用户提供数据转发平面的可编程能力的同时,保证数据的线性转发速率。
3. P4程序工作流程
至此,我们可以梳理出P4的完整工作流程。用户首先需要自定义数据帧的解析器和流控制程序,其次P4程序经过编译器编译后输出JSON格式的交换机配置文件和运行时的API,再次配置的文件载入到交换器中后更新解析起和匹配-动作表,最后交换机操作系统按照流控制程序进行包的查表操作。

图5 P4工作流程
如图5所示,以新增VLAN包解析为例,图中解析器除VXLAN以外的包解析是交换机中已有的,载入VXLAN.p4文件所得的配置文件的过程就是交换机的重配置过程。配置文件载入交换机后,解析器中会新增对VXLAN包解析,同时更新匹配-动作表,匹配成功后执行的动作也是在用户自定的程序中指定。执行动作需要交换机系统调用执行动作对应的指令来完成,这时交换机系统调用的是经过P4编译器生成的统一的运行时API,这个API就是交换机系统调用芯片功能的驱动,流控制程序就是指定API对应的交换机指令。
以上P4语言的特性、P4语言和P4交换机的工作原理和流程就介绍完毕了,希望能让不了解P4的人能有个基本的认识,同时起到抛砖引玉的作用。对P4感兴趣的同学可以加入到P4微信交流群中与大牛们一起讨论。邮箱:lengzhiyuan@fnii.com 微信号:cool_leng







