

导言
机器学习方法目前可以分为5个流派,分别是符号主义,联结主义,进化主义,贝叶斯和Analogzier。具体到实例有联结主义的神经网络,进化主义的遗传算法,贝叶斯的朴素贝叶斯(Naive Bayes)等等。
机器学习算法又可以分为多种类别,比如监督学习,无监督学习等。前者需要提供样本先进行训练。而无监督学习一般是针对没有标签的数据或者靠人力难以为数据打上标签的情况。例子:人脸识别。人与人之间会存在很多相似之处,比如各位明星的本体和模仿者,因为相似性是难以定义的,所以需要无监督学习进行聚类(clustering)。
在IDS系统中,为了阻止入侵,常见的方法有流量识别,DPI(深度数据包检测)等。本文的目的在于探索机器学习技术在流量分类上的应用,文中我采取了一些比较简单的例子来做实验。
在这个实验中,流量分类并不是单纯地针对每一个抓包结果进行分类,本文的目的是从关键的抓包结果来判断应用类别。因为这是离线分析,因此不探讨如何找到那些关键包。
在GFW中,似乎对于某些VPN应用的流量特征进行了学习,实际上只要识别加密流量是何种应用,就有办法实现干预。IDS也一样,只要能识别流量的特征,就可以在一定程度上阻止攻击。
很多机器学习算法都是基于概率论。在这个实验中,根据实验的目的,我采用的是基于概率论的朴素贝叶斯。
Naive Bayes
朴素贝叶斯是一种简单有效的分类算法(大多数机器学习算法无非是几个主要用途:分类,聚类,预测),适用于标称(离散)型数据,标称型数据即那些只能用自然数或整数单位计算的数据,比如人数、部门数,简单而言就是买菜不能买0.5棵,招人不能招2.4个人之类的。
优点:在数据较少时仍然有效,可以用于包含多种特征的样本分类。
缺点:对于数据的输入格式要求比较敏感。
实例
下面通过一个简单的例子(参考自阮一峰先生的日志)介绍朴素贝叶斯分类器:
有一个这样的样本:
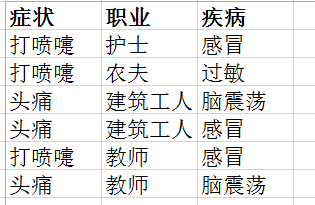
如果此时有一个头痛的建筑工人,则他患脑震荡的概率是?
由贝叶斯公式:P(A|B) = P(B|A)*P(A)/P(B)可得:
P(脑震荡|头痛x建筑工人) = P(头痛x建筑工人|脑震荡) x P(脑震荡) / P(头痛x建筑工人)
直接假定“头痛”和“建筑工人”特征互相独立,因此上式可以化为:
P(脑震荡|头痛x建筑工人) = P(头痛|脑震荡) x P(建筑工人|脑震荡) x P(脑震荡) /
P(头痛) x P(建筑工人)
因此:
P(脑震荡|头痛x建筑工人) = 1 x 0.5 x 0.33 / 0.5 x 0.33 = 1
因此该头痛的工人患脑震荡的概率是100%。可以计算这个病人患上感冒或过敏的概率。比较这几个概率,就可以知道他最可能得什么病。
多种模型
实际上,朴素贝叶斯包含三种模型,分别是高斯分布、伯努利分布和多项式:
高斯分布
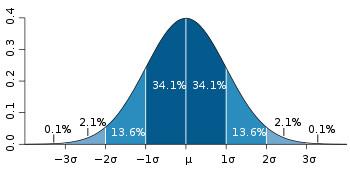
一般如果数据是连续的(比如身高,体重这些数据),则可以采用高斯分布模型的朴素贝叶斯。
伯努利分布
二项分布即重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关。这个模型的最简单例子就是抛硬币,要不正面或者反面。
多项式分布
多项式分布是伯努利分布的推广,但是实验结果不再服从二项分布,而是多个结果。就像掷色子,每个数字出现的次数则服从多项式分布。
在本实验中,因为会用到流量的多个特征,并且这些特征都是互相独立,特征内容也不仅仅是两个,因而采用多项式分布模型的朴素贝叶斯是最合适的。
思路
在虚拟机中部署多个应用,通过Wireshark抓包保存为pcap格式,再利用第三方工具提取特征,最后使用机器学习算法进行分类。因为本文并不是探讨如何实时监测数据包并即时进行反馈,本文更多是研究使用样本来对捕抓到的流量进行分类,作为尝试建立流量特征库的前提。
在实验中,会通过3个应用产生流量数据,分别是XMLRPC调用、REST API的调用和SOAP服务的访问。
XMLRPC所发送的协议为HTML/XML,包含了RPC的字段,REST传输的数据可以检查其中的内容,应该为JSON数据,SOAP则是可以看到HTTP方法和承载的XML数据。在实验中,假设已经能区分出哪些包是关键的:除去建立TCP连接和断开的相关包,找到交互的关键数据包。
一般来说流量分类可以基于下面的特征进行分类:源、目标MAC地址,源、目标IP地址,源、目标端口,IP协议版本、TCP源、目标端口,
TCP报文长度,使用的应用层协议,协议中的关键字段(XMLRPC的RPC2,浏览器HTTP的GET)
这个实验打算用MAC地址、IP地址、TCP目标端口、协议的关键字及部分Payload内容这几项特征进行分类。
由于在前面已经介绍了朴素贝叶斯的原理,因此在实验中将会使用现成的python库完成分类,我要做的是控制应用进行交互并产生数据,最后提取出数据构建样本,再交给现成的分类器进行分类。
准备工作
实验使用的几个应用的代码请参考我的github,本实验的全部代码和样本数据都在这个repo上:https://github.com/Hochikong/ML-SDN/tree/master/TEST1
实验的网络结构:

使用的现成的分类器是scikit-learn的sklearn.naive_bayes.MultinomialNB函数,sklearn是一个包含了很多工具的数据分析库,在naive_bayes中有三个函数,分别是GaussianNB、MultinomialNB和BernoulliNB,关于这些函数的使用方法可以阅读sklearn的页面:http://scikit-learn.org/stable/modules/naive_bayes.html,因为前文说到只有多项式分布模型合适本实验的流量分类,因此采用MultinomialNB函数。
下面利用这个现成的分类器做个简单的实验:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
>>> from numpy.random import randint as rd >>> X = rd(5,size=(6,7)) >>> X array([[4, 3, 3, 1, 0, 3, 3], [1, 1, 4, 0, 2, 1, 3], [2, 2, 4, 1, 4, 3, 4], [0, 4, 0, 2, 0, 2, 1], [0, 2, 0, 3, 3, 4, 2], [1, 0, 2, 1, 0, 0, 4]]) >>> y = ['a','b','c','d','e','f'] >>> from sklearn.naive_bayes import MultinomialNB >>> clf = MultinomialNB() >>> clf.fit(X,y) >>> print(clf.predict([1,1,5,1,4,1,3])) ['b'] >>> print(clf.predict([4,3,3,1,0,3,4])) ['a'] |
在上面这个例子中,X是样本,y是标签,fit()让样本对应每一个标签,因此当我们使用predict()进行分类时,将会利用样本算出输入数据的对应的标签。可以看到我输入了些结构与样本a和b行相似的数据,通过分类器成功判断出输入数据应该属于哪一类。
实际上,sklearn的朴素贝叶斯分类器并不能直接处理成员为字符串的输入数据,因此,流量中的字符串特征将会通过一个字典进行转换,转换为全部是数字的值,而标签是不限数据种类的,所以在实验中,标签将会使用字符串代表。
实验
制作样本
先生成基本的样本数据,通过下面几个交互过程产生必要的流量数据:
宿主访问VM1的REST API
VM2访问VM1的SOAP Service
VM1访问VM2的XMLRPC API
用Wireshark抓包后保存为pcap文件再使用scapy提取特征并转换为数字列表(实验中的样本数据已经上传到github,与实验代码同一个repo),下面是target.pcap的部分截图:
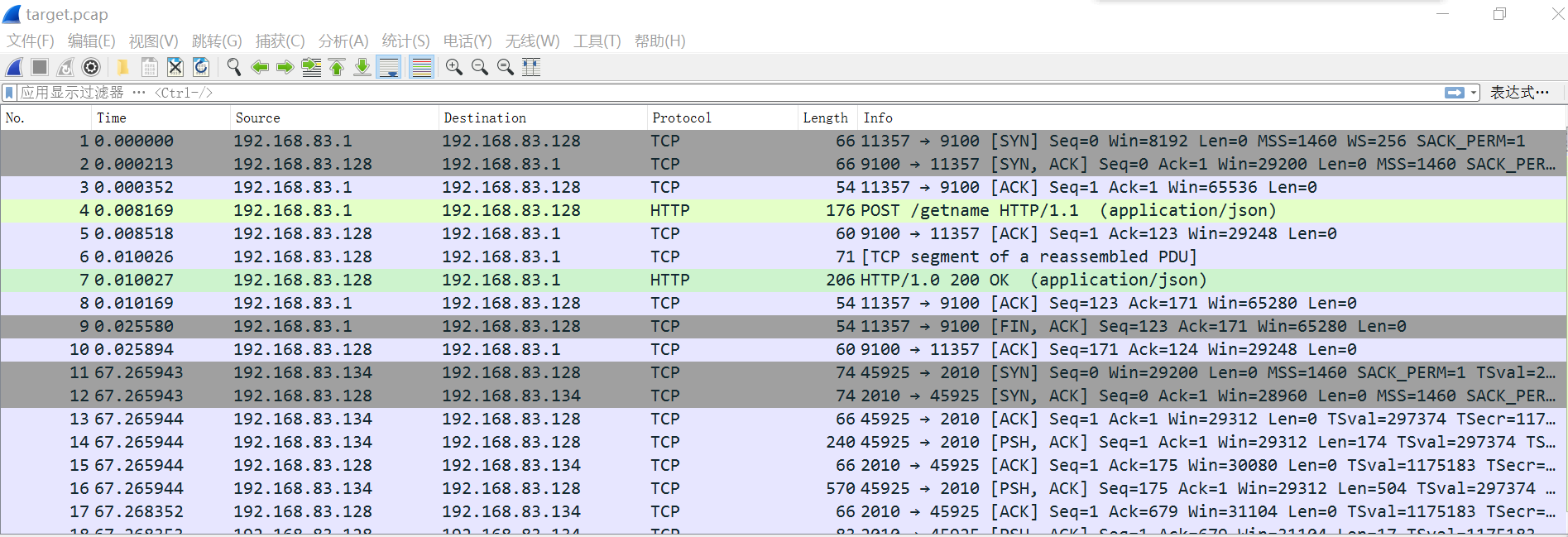
找到关键的数据包
从wireshark中查阅,找到关键的包,本实验中的是第4,14和30行:



如果你留意我的流量数据产生顺序,你就会怀疑为什么第14行中的协议只显示为TCP。
在wireshark中,应用的端口也会影响抓包结果的显示,我写了一篇blog,有兴趣了解其细节的读者可以参考我的blog:http://my.oschina.net/hochikong/blog/700882
找特征,建立翻译字典
然后进入scapy,为不同的应用选出需要的特征值:
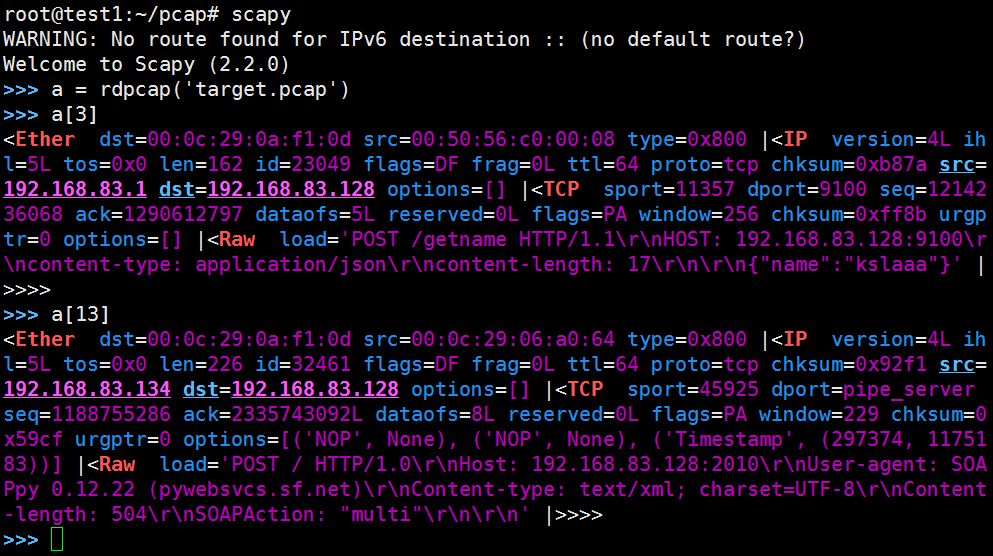
挑选出特征值,然后根据这些值建立相应的翻译字典,用一个独立的数字对应一个特征值,建立样本的数字序列。在后面通过一个程序抽取指定pcap行的数据特征并翻译为数字序列,最后通过分类器进行分类,决定该数据属于何种应用。
我建立的翻译字典是以样本中独一无二的那些特征为键,以从1到15的数字分别作为值,在python中打开dic.dat找DICT键下的数据就是该翻译字典:
|
1 2 3 4 |
>>> import shelve >>> f = shelve.open('dic.dat') >>> f {'DICT': {'192.168.83.128': 4, 'application/json': 2, '1300': 13, 'POST / HTTP': 8, '192.168.83.1': 6, 'POST /RPC2 HTTP': 12, '00:0c:29:06:a0:64': 9, '9100': 5, '00:0c:29:0a:f1:0d': 7, '00:50:56:c0:00:08': 3, '<methodCall>': 14, '192.168.83.134': 15, 'POST /getname': 1, 'SOAPAction': 11, '2010': 10}} |
当我们建好翻译字典,就可以着手从pcap文件提取样本的特征,并翻译为数字。
提取特征
先使用extra.py,提取第4、14和30行的数据:

这个程序要求先输入pcap文件位置,然后输入抽取的行数,以‘enough’结束,最后保存特征样本sample.tmp。
先检查下sample.tmp的内容:
|
1 2 3 4 |
>>> import shelve >>> f = shelve.open('sample.tmp') >>> f {'res': {4: ['00:50:56:c0:00:08', '192.168.83.1', '00:0c:29:0a:f1:0d', '192.168.83.128', '9100', 'POST /getname', 'application/json'], 14: ['00:0c:29:06:a0:64', '192.168.83.134', '00:0c:29:0a:f1:0d', '192.168.83.128', '2010', 'POST / HTTP', 'SOAPAction'], 30: ['00:0c:29:0a:f1:0d', '192.168.83.128', '00:0c:29:06:a0:64', '192.168.83.134', '1300', 'POST /RPC2 HTTP', '<methodCall>']}} |
可以看到,extra.py对上面指定的三行数据都进行了抽取,而排列顺序是根据srcMAC,srcIP,dstMAC,dstIP,dport,proto-key,payload-key这样来的。
暂停一下,思路呢?
关于最后两个特征,举个例子讲解下我是怎样选取特征的:
SOAPAPI的交互过程中,先建立TCP连接,再建立HTTP连接,然后传输SOAP Envelope,最后结束交互。
我这里只用建立HTTP连接的包作为关键包,因为SOAP是HTTP+XML(与XMLRPC一样),proto-key,其值是一个协议的关键字,我选的是能代表其传输协议HTTP的内容:'POST / HTTP',实际上这个特征只是scapy中该包的load一部分,可以看前第二幅图(scapy的截图)的load的内容。为何不选传输SOAP Envelope的那个包(在wireshark第16行)?
实际上,那个包并没有明显的HTTP的标识,只有SOAP Envelope:
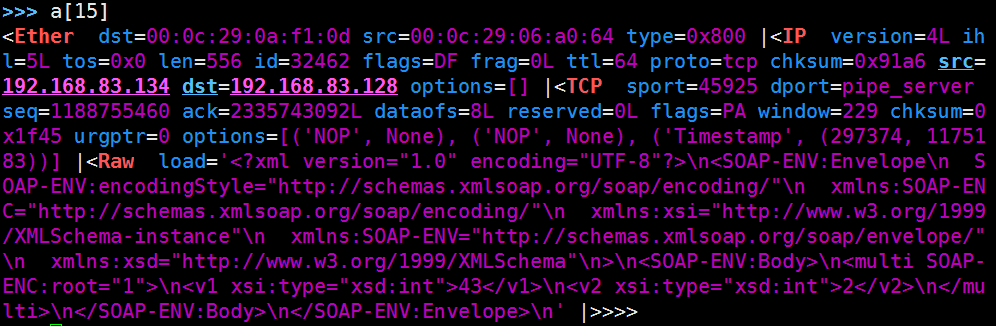
因为我要选的是协议关键字,所以针对SOAP Service,应该选择第14行的那个包。
对于payload-key,我也是在load这里找特征,对于SOAP应用,最好的莫过于'SOAPAction'。如果像RESTAPI一样用content-type,则会与XMLRPC冲突(两者都是text/xml),因为是SOAP Service,那么SOAP的关键字就是可以考虑的特征值了。
Keep going
然后我们可以着手翻译sample.tmp为数字序列并提供对应的label了,我需要执行samtran.py:

执行时若没有任何错误,则自动生成一个tranres.dat的数据,同样查看一下该数据文件:
|
1 2 3 4 |
>>> import shelve >>> f = shelve.open('tranres.dat') >>> f {'res': {'sample': [[3, 6, 7, 4, 5, 1, 2], [9, 15, 7, 4, 10, 8, 11], [7, 4, 9, 15, 13, 12, 14]], 'label': ['RESTAPI', 'SOAPAPI', 'XMLRPC']}} |
这样一来就完成了分类的所有准备。
分类前的准备
接下来,修改应用,改变部署的位置,采用不同的client,制造新的流量数据,并用上面准备的样本,使用朴素贝叶斯进行分类。
应用的部署和修改如下:
1.VM1换端口启动RESTAPI,VM2使用客户端与其交互
2.VM2启动SOAPAPI,使用一个未在网络规划中用到的VM3与其交互
3.VM3换端口启动XMLRPC,host调用XMLRPC接口
应用交互产生的数据包保存为exp.pcap。通过分析wireshark的抓包结果,分别找出关键的内容的行数为:4(REST)、18(SOAP)和34(XMLRPC),外加与XMLRPC有关的建立TCP连接的包第31行。
通过extra.py抽取特征,并把特征保存为exp.tmp:
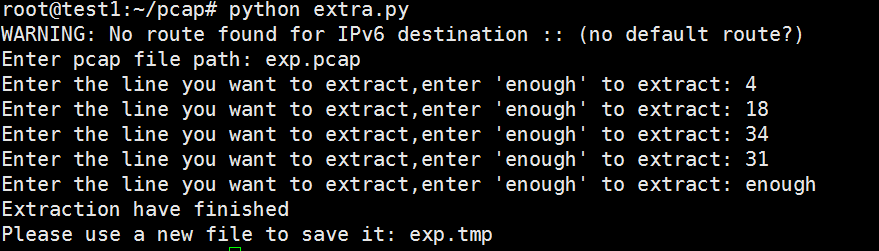
检查下抽取成果:

可以看到,对于不包含我预先设定的三种proto-key和payload-key,会给该值为unknown。
翻译为数字序列,这里用到的是gentran.py:

在前面extra.py保存数据时对第31行的proto-key和payload-key的值都设置为unknown,gentran.py对于这些unknown值或者是没有在翻译字典中出现的值都会使用一个从16到25的随机数作为翻译结果。
最后看看翻译后的数字序列:
|
1 2 |
>>> a {'res': {18: [23, 21, 9, 15, 10, 8, 11], 4: [9, 15, 7, 4, 23, 1, 2], 34: [3, 6, 16, 20, 24, 12, 14], 31: [3, 6, 20, 24, 17, 19, 25]}} |
Last Station
载入exp.dat和tranres.dat,分别作为被分类对象和样本:
|
1 2 3 4 5 6 7 |
>>> import shelve >>> a = shelve.open('exp.dat') >>> a {'res': {18: [23, 21, 9, 15, 10, 8, 11], 4: [9, 15, 7, 4, 23, 1, 2], 34: [3, 6, 16, 20, 24, 12, 14], 31: [3, 6, 20, 24, 17, 19, 25]}} >>> b = shelve.open('tranres.dat') >>> b {'res': {'sample': [[3, 6, 7, 4, 5, 1, 2], [9, 15, 7, 4, 10, 8, 11], [7, 4, 9, 15, 13, 12, 14]], 'label': ['RESTAPI', 'SOAPAPI', 'XMLRPC']}} |
简化一下操作所需的准备:
|
1 2 3 4 5 6 |
>>> sample = b['res']['sample'] >>> sample [[3, 6, 7, 4, 5, 1, 2], [9, 15, 7, 4, 10, 8, 11], [7, 4, 9, 15, 13, 12, 14]] >>> labels = b['res']['label'] >>> labels ['RESTAPI', 'SOAPAPI', 'XMLRPC'] |
导入sklearn分类器,创建一个分类器对象并设置好样本和标签:
|
1 2 3 4 |
>>> from sklearn.naive_bayes import MultinomialNB >>> clf = MultinomialNB() >>> clf.fit(sample,labels) MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True) |
分类操作:
|
1 2 3 4 5 6 7 8 |
>>> print(clf.predict(expobj[18])) ['SOAPAPI'] >>> print(clf.predict(expobj[4])) ['RESTAPI'] >>> print(clf.predict(expobj[31])) ['XMLRPC'] >>> print(clf.predict(expobj[34])) ['XMLRPC'] |
可以看到,我们通过把流量特征转化为数字序列,用sklearn的朴素贝叶斯分类器成功地对流量进行分类。(expobj其实是a['res'])
就算不是我要找的关键的包(31),但由于与XMLRPC有关,特征比较相近,因此也被判断为XMLRPC应用所发出的包。
结语
在本实践中,由于被分类的数据量比较小,因此没办法检测分类器的准确度,如果有更多应用和被分类数据,就可以测试分类器在流量分类上的准确度。
本实践通过人工找出每一个应用关键的数据包,然后通过工具提取这些包的关键特征用以区分应用类别。因为sklearn的朴素贝叶斯分类器不支持字符串样本,因此需要手工建立一个用于把特征翻译为数字序列的字典文件,最后通过提取工具,提取被分类数据的关键包,交给翻译程序翻译为数字序列。最后使用sklearn的分类器对流量进行分类,并验证分类结果。
通过建立流量特征值库,就可以利用这个库对收集回来的流量进行分类或者分析,并应用到IDS的策略上以实现对指定应用的数据传输的限制。文中只采用了简单的基于HTTP明文传输的应用,对于加密的流量或者P2P应用,还需要更高级的手段对payload进行解包和分析以进行特征提取。
本文通过实验把机器学习应用到了离线流量分类的用途上,提供了一个思路,希望能对读者有所帮助。
本人水平有限,如果有任何错误或疏漏之处,还请多多包涵。
参考资料:
http://synchuman.baijia.baidu.com/article/247257
http://www.360doc.com/content/16/0327/15/478627_545630965.shtml
http://blog.csdn.net/lsldd/article/details/41542107
http://blog.csdn.net/march_on/article/details/48767679
http://www.ruanyifeng.com/blog/2013/12/naivebayesclassifier.html
http://blog.csdn.net/iloveyin/article/details/21444613
http://www.secdev.org/projects/scapy/doc/usage.html
作者简介:
何智刚,2015至今,准大学生一枚,主要研究云计算、SDN、机器学习,对各种领域都有所涉猎,目标是迈向full stack。
qq:1097225749
github:https://github.com/Hochikong








