

有关SFC的某些基本概率就不在这里做过多阐述,相关内容可以参看其他小伙伴写的文章.SDNLAB技术分享(一):ODL的SFC入门和Demo。
本文所有源码不是OVS主线版本,目前OVS主线版本还没有实现NSH解析功能。该版本的OVS为私有版本,github网址见下方:https://github.com/tfherbert/ovs_Pritesh_V8/tree/nsh-v8
1. NSH-SFC概述
当前SFC的实现方案主要分为两种:一种基于NSH(network service header)。数据封装时,在L2或者L3数据后添加NSH头,然后进行L3或L4的封装。转发时,根据nshheader去转发SFC中的数据,整个过程都是依据同一个SPI(service path id)和递减的SI(service index);另一种无NSH头,在转发过程中,SFF需要不停对新来的数据包进行判断,确定是否属于某个SFC。ODL的子项目SFC就是第一种的实现。
1.1 NSH-SFC组件简述
Classifier:分类器,根据controller来的policy来决策是否给数据进行nsh封装,并且把数据发送至相应的sff。
Service Function(SF):网络中的Middleware,常见的有loadbalance,firework,NAT等。值得注意的是,在NSH方案下,如果SF没有NSH解析功能,那么需要在SF和其对应的SFF之间增加一个proxy。该proxy用于解析NSH,并且帮助完成nshheader中SI的自减算法(如果SI不能成功自减,那么SFF会认为这个数据没有被forward到该SF,从而再次forward向该SF,最后的结果就是产生网络风暴)。
Service Function Forwarder(SFF):SFC中的数据中转站,负责数据的转发。当SI=1的时候,SFF负责把nsh头部去掉。
1.2 NSH-SFC(with VxLAN)工作流程

- 控制层面定义SFC:
- 用户利用SDN提供的北向应用,创建sfc1,controller会做相应的配置工作,产生对应的数据通道(sfc1本身是一个chain,可以和vxlan的tunnel完美匹配。那么,定义了sfc1,同时可以对应一个vxlan。所以,可以理解为sfc1同时绑定了vxlan和NSH中的path信息)。
- 数据首先通过classifier,classifier为sfc1的数据打上nsh头信息,然后转交sff1。
- sff1将数据发送至sf1,sf1将数据处理完后,为nshheader中的si执行自减操作,然后返回到sff1.
- sff1将数据交到sff2,sff2重复sff的职责...
- 对于没有nsh解析能力的sf2,proxy会帮其完成nsh相关工作.
- 在si=0(有文档说si=1)的时候,sff会给数据包去nsh,那么整个sfc1流程就结束
1.3 VxLAN存在的意义
首先,NSH不一定需要依托于VxLAN,GRE + NSH、VXLAN-gpe + NSH、Ethernet + NSH都是可行的方案。其实,NSH只是一个封装技术,起了一个标签的作用,本身并不会影响传输。 在SFC中,很重要的一点是SFF能够尽快、准确地把带NSH头的数据包转发出去。那么,SFF需要做的工作实际根据nshheader去择路,而SFF中的路是controller通过流表已经创建好了的。所以,进一步说,SFF只需要把NSH头和某个流表统一起来即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
struct sw_flow { struct rcu_head rcu; struct hlist_node hash_node[2]; u32 hash; int stats_last_writer; /* NUMA-node id of the last writer on * 'stats[0]'. */ struct sw_flow_key key; //流表匹配时候用到的key值 struct sw_flow_key unmasked_key; struct sw_flow_mask *mask; struct sw_flow_actions __rcu *sf_acts; struct flow_stats __rcu *stats[]; /* One for each NUMA node. First one * is allocated at flow creation time, * the rest are allocated on demand * while holding the 'stats[0].lock'. */ }; struct sw_flow_key { u8 tun_opts[255]; u8 tun_opts_len; struct ovs_key_ipv4_tunnel tun_key; //该流表对应的tunnel信息 ....... } struct ovs_key_ipv4_tunnel { __be64 tun_id; __be32 nsp; /* it contains (nsp - 24 bits | nsi - 8 bits) here */ __be32 nshc1; /* NSH context headers */ __be32 nshc2; __be32 nshc3; __be32 nshc4; __be32 ipv4_src; __be32 ipv4_dst; __be16 tun_flags; u8 ipv4_tos; u8 ipv4_ttl; } __packed __aligned(4); /* Minimize padding. */ |
每个openflow流表去匹配的时候,sw_key结构体是匹配的关键,该结构体包含了隧道信息。而nshheader本身的SPI就可以看成一种隧道信息,那么用vxlan便很轻易的统一起来了。
综合起来,VxLAN的tunnel信息和openflow流表就可以统一起来了。
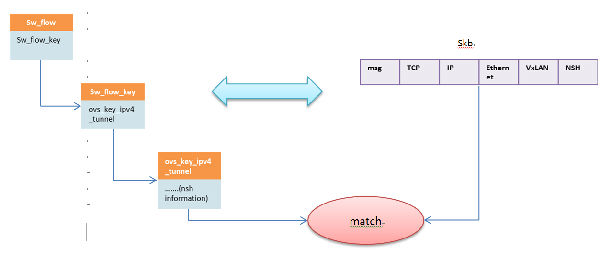
上图其实也是sff去匹配流表的过程。
2. OVS源码解读。
首先是NSH和VxLAN的header结构体。
2.1NSHheader和VxLANheader结构体
NSH
|
1 2 3 4 |
struct nshhdr { struct nsh_base b; struct nsh_ctx c; }; |
很清楚的表明:包含base和ctx部分,其中base尤为重要,包含了路径信息;ctx用于sf之间传递metadata。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
struct nsh_base { #if defined(__LITTLE_ENDIAN_BITFIELD) //小端序 __u8 res1:4; __u8 c:1; __u8 o:1; __u8 ver:2; __u8 len:6; __u8 res2:2; #elif defined(__BIG_ENDIAN_BITFIELD) //大端序 __u8 ver:2; __u8 o:1; __u8 c:1; __u8 res1:4; __u8 res2:2; __u8 len:6; #else #error "Bitfield Endianess not defined." #endif __u8 mdtype; //mdtype决定了ctx的格式 __u8 proto; //next protocol union { struct { __u8 svc_path[3]; //spi __u8 svc_idx; //si }; __be32 b2; }; }; |
base的结构体
|
1 2 3 4 5 6 |
struct nsh_ctx { __be32 c1; __be32 c2; __be32 c3; __be32 c4; }; |
ctx结构体
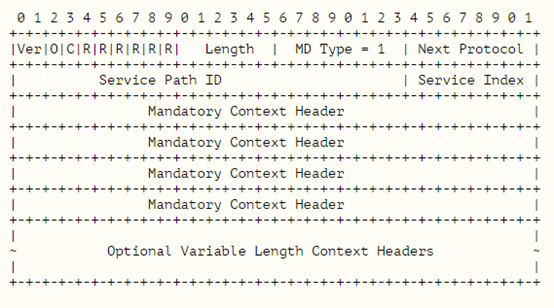
协议图
VxLANheader
|
1 2 3 4 |
struct vxlanhdr { __be32 vx_flags; __be32 vx_vni; }; |
vni是重点
|
1 2 3 4 |
#define VXLAN_HLEN (sizeof(struct udphdr) + sizeof(struct vxlanhdr)) #define NSH_HLEN (sizeof(struct udphdr) + \ sizeof(struct vxlanhdr) + \ sizeof(struct nshhdr)) |
这部分代码说明了数据包封装过后的格式,如下图(请无视gpe)

2.2 VxLAN的创建和数据的监听和处理
首先介绍下linux内核中sock和socket还有skb。
socket和sock的区别和联系:大家都是socket通信中的socket,不过应用的网络层次有区别。socket主要作用于Linux系统中的BSD层(L6层),INET层很少应用, BSD和INET层分别对应ISO中的表示层和会话层,其结构体相对sock而言比较简单;而sock贯穿了硬件层和设备接口层和IP层INET层,贯穿了L2-L5层,而且是各层之间相互联系的重要纽带。
skb:sk_buff 是网络数据报在内核中的表现形式,数据包在内核协议栈中是通过skb的数据结构来实现的。
|
1 2 3 4 5 6 7 8 |
union { struct tcphdr *th; //传输层tcp,指向首部第一个字节位置 struct ethhdr *eth; //链路层上,指向以太网首部第一个字节位置 struct iphdr *iph; //网络层上,指向ip首部第一个字节位置 struct udphdr *uh; //传输层udp协议, unsigned char *raw; //随层次变化而变化,链路层=eth,网络层=iph unsigned long seq; //针对tcp协议的待发送数据包而言,表示该数据包的ACK值 } h; |
这部分代码是sk_buffer结构体中的联合体,很明显可以看出来skb贯穿了协议栈的各层。
下面是VxLAN的创建过程:
1、vport.c定义了实现了vport最基本的或者共有的一些功能, 如添加、删除等功能,还有数据的收发功能。
2、vport-XXX.c是vport基于其他的一些个性化实现,如vport-vxlan.c实现了一些vxlan的功能:tunnel的创建、删除等。
2.2.1 OVS相关socket结构体
|
1 2 3 4 5 6 7 8 9 |
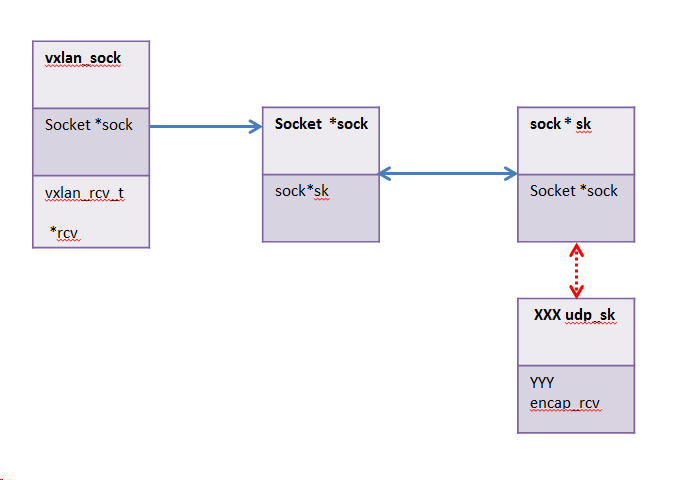
/* per UDP socket information */ struct vxlan_sock { struct hlist_node hlist; vxlan_rcv_t *rcv; //数据处理函数,在收到数据后回调该函数 void *data; struct work_struct del_work; //调用linux内核工作队列需要用到的结构体, 该结构体定义了新启线程需要完成的工作的抽象 struct socket *sock; struct rcu_head rcu; //linux线程锁 }; |
上面是VxLAN对应的socket,注意其中的struct socket *sock; 他名字叫做sock,其实是socket结构体的实例。
接着看struct socket *sock对应的结构体(linux内核中的函数)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
struct socket { socket_state state; unsigned long flags; struct proto_ops *ops; struct inode *inode; struct fasync_struct *fasync_list; /* Asynchronous wake up list */ struct file *file; /* File back pointer for gc */ struct sock *sk; //指向sock wait_queue_head_t wait; short type; unsigned char passcred; }; |
注意struct sock *sk; 指向了sock。sock的结构体就不贴了,但是要注意的是sock中也有指向socket的指针,还有指向数据处理函数的指针。
综合起来,VxLAN中的几个socket联系如下:
2.2.2 VxLAN的创建过程,packet和流表的匹配
在用ovs-vsctl工具下命令创建VxLAN的时候,会去调用vport-vxlan.c中的ovs_vxlan_vport_ops.create命令,对应函数如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
static struct vport *vxlan_tnl_create(const struct vport_parms *parms) { struct net *net = ovs_dp_get_net(parms->dp); struct nlattr *options = parms->options;//vxlan struct vxlan_port *vxlan_port; struct vxlan_sock *vs; struct vport *vport; struct nlattr *a; u16 dst_port; int err; if (!options) { //option数据不能为空 err = -EINVAL; goto error; } a = nla_find_nested(options, OVS_TUNNEL_ATTR_DST_PORT); //从option中提取dst port if (a && nla_len(a) == sizeof(u16)) { dst_port = nla_get_u16(a); } else { /* Require destination port from userspace. */ err = -EINVAL; goto error; } vport = ovs_vport_alloc(sizeof(struct vxlan_port), //初始化vport,&ovs_vxlan_vport_ops是 vport相关的操作,此处为默认的几种,可以自己添加 &ovs_vxlan_vport_ops, parms); /*struct vport *ovs_vport_alloc(int priv_size, const struct vport_ops *ops, const struct vport_parms *parms)*/ if (IS_ERR(vport)) //初始化是否成功 return vport; vxlan_port = vxlan_vport(vport); //为vxlan_vport分配私有数据区 strncpy(vxlan_port->name, parms->name, IFNAMSIZ); vs = vxlan_sock_add(net, htons(dst_port), vxlan_rcv, vport, true, false); //为vport创建 vxlan_sock if (IS_ERR(vs)) { //判断是否创建成功 ovs_vport_free(vport); return (void *)vs; } vxlan_port->vs = vs; return vport; error: return ERR_PTR(err); } |
这个函数中比较重要的是vxlan_port = vxlan_vport(vport)和vxlan_sock_add(net, htons(dst_port), vxlan_rcv, vport, true, false);
- vxlan_port = vxlan_vport(vport)为该VxLAN的port申请私有数据区,该数据区可以存放任何数据。这也为逻辑端口vport和物理端口net_device提供绑定的空间。事实上,vport和net-device之间还隔着一个结构体netdev_vport,该数据区就可以用在存放vport对应的netdev_port。
- vs = vxlan_sock_add(net, htons(dst_port), vxlan_rcv, vport, true, false)把vxlan_rcv数据处理函数注册到了vs中。
为了思路的连续性,我们先接着看主线vxlan_sock_add,最后回头再看数据处理部分。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
struct vxlan_sock *vxlan_sock_add(struct net *net, __be16 port, vxlan_rcv_t *rcv, void *data, bool no_share, bool ipv6) { return vxlan_socket_create(net, port, rcv, data); } static struct vxlan_sock *vxlan_socket_create(struct net *net, __be16 port, vxlan_rcv_t *rcv, void *data) { struct vxlan_sock *vs; //最后返回的vs struct sock *sk; struct sockaddr_in vxlan_addr = { .sin_family = AF_INET, .sin_addr.s_addr = htonl(INADDR_ANY), .sin_port = port, }; int rc; vs = kmalloc(sizeof(*vs), GFP_KERNEL); //为vs分配内存 if (!vs) { pr_debug("memory alocation failure\n"); return ERR_PTR(-ENOMEM); } INIT_WORK(&vs->del_work, vxlan_del_work); //调用linux内核中工作队列,去执行del工作 /* Create UDP socket for encapsulation receive. */ rc = sock_create_kern(AF_INET, SOCK_DGRAM, IPPROTO_UDP, &vs->sock);//创建用于接收udp包的socket if (rc < 0) { pr_debug("UDP socket create failed\n"); kfree(vs); return ERR_PTR(rc); } /* Put in proper namespace */ sk = vs->sock->sk; sk_change_net(sk, net); rc = kernel_bind(vs->sock, (struct sockaddr *) &vxlan_addr, //将刚刚创建的socket和正在创建的vxlan绑定 , 其中vs->sk指向该socket kernel_bind为Linux内核里面的绑定函数 sizeof(vxlan_addr)); if (rc < 0) { pr_debug("bind for UDP socket %pI4:%u (%d)\n", &vxlan_addr.sin_addr, ntohs(vxlan_addr.sin_port), rc); sk_release_kernel(sk); kfree(vs); return ERR_PTR(rc); } vs->rcv = rcv; vs->data = data; /* Disable multicast loopback */ inet_sk(sk)->mc_loop = 0; rcu_assign_sk_user_data(vs->sock->sk, vs); /* Mark socket as an encapsulation socket. */ udp_sk(sk)->encap_type = 1; //将sk转换成udp内部使用的sk类型, udp_sk(sk)->encap_rcv = vxlan_udp_encap_recv; //绑定vxlan收到udp包后的处理函数 udp_encap_enable(); return vs; } |
- vs->rcv = rcv;
- sk = vs->sock->sk;
- udp_sk(sk)->encap_rcv = vxlan_udp_encap_recv;
主线到这里就算结束了,最后的结果是创建了一个vxlan_sock和一个socket和一个sock,中间的socket只是一个索引,vxlan_sock->socket->sock。其中vxlan_sock和sock注册了各自的数据处理函数。 一个很重要的点是:在linux内核中,无论收发数据,都会被缓存到sock 结构中的缓冲队列中。
整理下主线结构:
创建vxlan的流程
ovs_vport_add->vport_ops_list[i].create->ovs_vxlan_vport_ops.create->
vxlan_tnl_create->vxlan_sock_add->vxlan_socket_create.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
/* Callback from net/ipv4/udp.c to receive packets */ static int vxlan_udp_encap_recv(struct sock *sk, struct sk_buff *skb) { struct vxlan_sock *vs; struct vxlanhdr *vxh; struct udphdr *udp; bool isnsh = false; __be32 nsp = 0; __be32 c1 = 0; __be32 c2 = 0; __be32 c3 = 0; __be32 c4 = 0; udp = (struct udphdr *)udp_hdr(skb); if (udp->dest == htons(NSH_DST_PORT)) //根据udp目的端口(6633)来判断是否含有nsh isnsh = true; //htons HBO to NBO /* Need Vxlan and inner Ethernet header to be present */ if (!pskb_may_pull(skb, isnsh ? NSH_HLEN : VXLAN_HLEN)) // 检查skb长度是否能够满足把后面的头部去掉 如果不够返回-1 报错 goto error; /* Return packets with reserved bits set */ vxh = vxlan_hdr(skb); //提取vxlanheader if (vxh->vx_flags != htonl(VXLAN_FLAGS) || (vxh->vx_vni & htonl(0xff))) { pr_warn("invalid vxlan flags=%#x vni=%#x\n", ntohl(vxh->vx_flags), ntohl(vxh->vx_vni)); goto error; } if (isnsh) { struct nshhdr *nsh = nsh_hdr(skb); if (unlikely(nsh->b.svc_idx == 0 || nsh->b.ver || //如果 si == 0 sfc结束,直接drop nsh->b.len != 6 || nsh->b.mdtype != 0x01 || nsh->b.proto != NSH_P_ETHERNET)) { pr_warn("NSH service index reached zero or not supported\n"); goto drop; } nsp = nsh->b.b2; /* same as svc_path | htonl(svc_idx) */ c1 = nsh->c.c1; /* NSH Contexts */ c2 = nsh->c.c2; c3 = nsh->c.c3; c4 = nsh->c.c4; } if (iptunnel_pull_header(skb, isnsh ? NSH_HLEN : VXLAN_HLEN, htons(ETH_P_TEB))) goto drop; vs = rcu_dereference_sk_user_data(sk); if (!vs) goto drop; vs->rcv(vs, skb, vxh->vx_vni, nsp, c1, c2, c3, c3); //调用vs->rcv,即 return 0; drop: /* Consume bad packet */ kfree_skb(skb); return 0; error: /* Return non vxlan pkt */ return 1; } |
上面这个为sock注册过的处理函数,主要工作是一层层的剥开skb的封装(当然,里面会判断是否含有nshheader),提取udp,vxlan 和nshheader的头部信息。
- sock在之前被强制转换成了udp的socket,该函数由linux内核中net/ipv4/udp.c回调.
- if (udp->dest == htons(NSH_DST_PORT)) nsh的判断依据
- si=0 的时候,sfc结束,drop packet
- 核心调用 vs->rcv(vs, skb, vxh->vx_vni, nsp, c1, c2, c3, c3);
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
static void vxlan_rcv(struct vxlan_sock *vs, struct sk_buff *skb, __be32 vx_vni, __be32 nsp, __be32 nshc1, __be32 nshc2, __be32 nshc3, __be32 nshc4) { struct ovs_tunnel_info tun_info; struct vport *vport = vs->data; struct iphdr *iph; __be64 key; /* Save outer tunnel values */ iph = ip_hdr(skb); key = cpu_to_be64(ntohl(vx_vni) >> 8); ovs_flow_tun_info_init(&tun_info, iph, key, nsp, nshc1, nshc2, nshc3, nshc4, TUNNEL_KEY | TUNNEL_NSP | TUNNEL_NSI | TUNNEL_NSHC, NULL, 0); ovs_vport_receive(vport, skb, &tun_info); //回到vport.c中处理 }0 |
该函数最重要的一句无疑是ovs_vport_receive(vport, skb, &tun_info).
之前的工作实际是进一步整合传入的header信息,用ovs_flow_tun_info_init去初始化tun_info,然后调用vport中数据处理函数ovs_vport_receive进一步处理。
事实上,不论vxlan还是gre亦或lisp网络,最后的数据处理都会回到ovs_vport_receive,然后在ovs_vport_receive去调用ovs_dp_process_received_packet,回到datapath.c进行统一处理;在ovs_dp_process_received_packet进行流表查询,然后去查表执行对应的action。
在查询流表失败的时候,由ovs_dp_upcall发送upcall到用户空间(ovs-vswitchd),此后处理过程交给ovsd 处理。具体的流表匹配就不展开了。
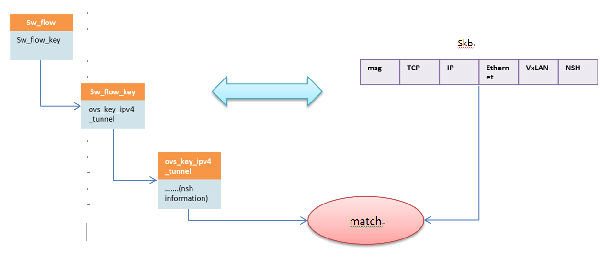
以上数据监听到处理的流程解读实际上说明了OVS已经把VxLAN的tunnel信息和NSH信息整合起来了,流表和数据的对应关系如上图。
2.3 OVS作为classifier对数据进行的NSH封装
OVS作为classifier最重要的功能就是对数据的封装和发送。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
int vxlan_xmit_skb(struct vxlan_sock *vs, struct rtable *rt, struct sk_buff *skb, __be32 src, __be32 dst, __u8 tos, __u8 ttl, __be16 df, __be16 src_port, __be16 dst_port, __be32 vni, __be32 nsp, __be32 nshc1, __be32 nshc2, __be32 nshc3, __be32 nshc4) { bool isnsh = (dst_port == htons(NSH_DST_PORT)); struct vxlanhdr *vxh; struct udphdr *uh; int min_headroom; int err; min_headroom = LL_RESERVED_SPACE(rt_dst(rt).dev) + rt_dst(rt).header_len + (isnsh ? NSH_HLEN : VXLAN_HLEN) + sizeof(struct iphdr) + (vlan_tx_tag_present(skb) ? VLAN_HLEN : 0);//最小长度 /* Need space for new headers (invalidates iph ptr) */ err = skb_cow_head(skb, min_headroom); //验证skb长度是否足够 if (unlikely(err)) return err; if (vlan_tx_tag_present(skb)) { if (unlikely(!__vlan_put_tag(skb, skb->vlan_proto, vlan_tx_tag_get(skb)))) return -ENOMEM; vlan_set_tci(skb, 0); } skb_reset_inner_headers(skb); if (isnsh) { struct nshhdr *nsh; uint8_t nsi = ntohl(nsp) & NSH_M_NSI; nsh = (struct nshhdr *) __skb_push(skb, sizeof(*nsh));//把nsh头push到skb中 nshheader封装 memset(&nsh->b, 0, sizeof nsh->b); //初始化nsh_b nsh->b.len = 6; nsh->b.mdtype = NSH_M_TYPE1; nsh->b.proto = NSH_P_ETHERNET; /* b2 should precede svc_idx, else svc_idx will be zero */ nsh->b.b2 = nsp & htonl(NSH_M_NSP); nsh->b.svc_idx = nsi ? nsi : 0x01; nsh->c.c1 = nshc1; nsh->c.c2 = nshc2; nsh->c.c3 = nshc3; nsh->c.c4 = nshc4; } vxh = (struct vxlanhdr *) __skb_push(skb, sizeof(*vxh)); //vxlanheader封装 vxh->vx_flags = htonl(VXLAN_FLAGS); vxh->vx_vni = vni; __skb_push(skb, sizeof(*uh)); //udp header封装 skb_reset_transport_header(skb); uh = udp_hdr(skb); uh->dest = dst_port; uh->source = src_port; uh->len = htons(skb->len); uh->check = 0; vxlan_set_owner(vs->sock->sk, skb); //把skb 绑定的到某个vxlan的sk, 实际是为vxlan设置skb err = handle_offloads(skb); if (err) return err; return iptunnel_xmit(vs->sock->sk, rt, skb, src, dst, IPPROTO_UDP, //iptunnel封装 tos, ttl, df, false); } |
linux内核中vxlan_xmit_skb函数的功能是对skb进行vxlan封装,在OVS中对该函数进行了重写,增加了NSH封装功能。
该函数在vxlan的send操作被调用,即在classifier发数据前进行了封装。另外,该版本OVS添加了NSH对应的action,主要是一些attribute动作,用于添加NSH信息。
3. 总结
- OVS在SFC-NSH中,可以是Classifier,SFF和SF对应的proxy.
- 该版本OVS添加了NSH对应的action,主要是attribute,用于添加NSH,这部分功能主要用于classifier去打NSHheader。
- NSH只是一个封装技术,便于SFC中的数据传输。
作者简介: 张萌 2014.9-今在北邮计算机学院网络技术中心学习
--------------华丽的分割线------------------
本文系《SDNLAB原创文章奖励计划》投稿文章,该计划旨在鼓励广大从业人员在SDN/NFV/Cloud网络领域创新技术、开源项目、产业动态等方面进行经验和成果的文字传播、分享、交流。有意向投稿的同学请通过官方唯一指定投稿通道进行文章投递,投稿细则请参考《SDNLAB原创文章奖励计划》






