

上一节仔仔细细地看了虚拟机的启动过程,这一节我们来看看Neutron中的OVS是如何支持虚拟机间的通信的。
======================== 分隔线 ===========================
在具体介绍OVS的工作机制之前,读者要先理解OVS并不是Neutron网络实现的唯一选择。
实际上,Neutron中底层网络的实现千差万别:有的agent本地是真正处理数据流的网络设备(OVS,Router,LoadBalancer等),而有的agent本地是SDN控制器(如ODL、ONOS、OpenContrail、NSX等)。上述Neutron底层网络的两种模型示意如下。

第一种模型中Neutron相当于SDN控制器,plugin与agent间的通信机制(如rpc)就相当于简单的南向协议。第二种模型中Neutron作为SDN应用,将业务需求告知SDN控制器,SDN控制器再通过五花八门的南向协议远程控制网络设备。当然,第二种模型中也可以把Neutron看做超级控制器或者网络编排器,去完成OpenStack中网络业务的集中分发。
以下我们讲的是第一种模型中OVS处理数据流的工作机制。后一种模型中,SDN控制器也可以通过OpenFlow或者OVSDB来控制OVS处理数据流,对此本节暂时不进行讨论,后续讲到ODL和ONOS等SDN控制器的时候再来介绍。
======================== 分隔线 ===========================
以Overlay组网模型对OVS的工作机制进行介绍,具体分为两个角度:OVS实现L2的基本连接,OVS对连接机制的优化。
(一)L2基本连接的实现
复原一下通信场景,其中的网络基础请参考“OpenStack网络基础”一小节。图中某租户有两个网段,分别用橙红色和蓝色表示,网段间的互通要经过网络节点中的Router,网段内的通信不需要经过网络节点中的Router。网段间的互通可分为3步:橙红色网段通过网段内通信找到Router,Router进行路由,Router通过蓝色网段的网段内通信转发给目的地。Router上的路由是linux内核实现的,我们不去关心,因此可以说租户内部通信都是基于网段内通信实现的。

Overlay模型中,网段内通信涉及ovs br-int和ovs br-tun,计算节点和网络节点中两类网桥的实现没有什么区别。概括地说,br-int负责在节点本地的网段内通信,br-tun则负责节点间的网段内通信。
在本节的场景内br-int实现为普通的二层交换机,即完成VLAN标签的增删和正常的二层自学习与转发,没有必要进行过多的解释,其代码实现请参考“Neutron的软件实现”中agent部分。
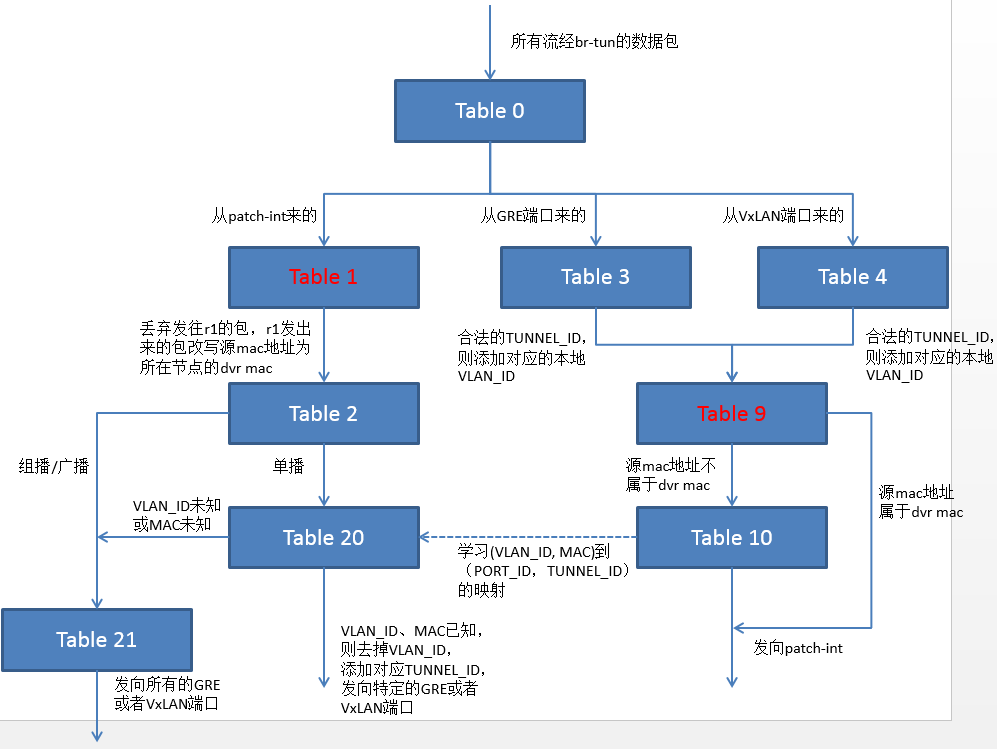
Br-tun采用多级流表实现节点间的网段内通信,下面直接通过图示来看br-tun中多级流表的设计。图中流表的序号不是固定的,可在neutron.plugins.openvswitch.agent.common目录下的constants.py文件中修改。
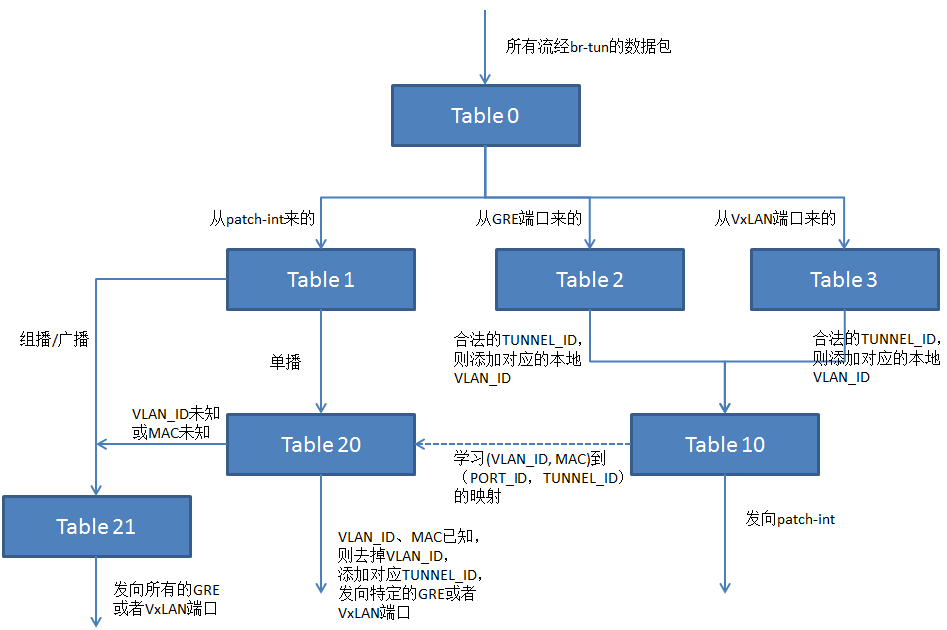
所有流经br-tun的数据包首先进入Table 0进行处理。Table 0对数据包的来源进行判断,从与br-int相连的patch-int进入的数据包交给Table 1处理,从GRE或者VxLAN端口(不同节点间的隧道有不同的Port_ID)进入的分别交给Table 2、Table 3处理。Table 1根据数据包目的MAC地址判断是否为单播,是则送往Table 20,否则送往Table 21,Table 20根据(VLAN_ID,MAC)到(PORT_ID,TUNNEL_ID)的映射关系将单播包送到特定的隧道,Table 21将非单播包复制后送到所有隧道。进入Table 2或者Table 3的数据包,首先判断TUNNE_ID是否合法,是则添加本地VLAN_ID并送往Table 10,否则丢弃。Table 10记录数据包的VLAN_ID,MAC、入端口以及TUNNEL_ID,将(VLAN_ID,MAC)到(PORT_ID,TUNNEL_ID)的映射关系写入Table 20,然后将数据包从与br-int相连的patch-int送出。上述流表具体表示如下:
=====================Tables in br-tun ==========================
Table 0:
table=0, priority=1, in_port=patch_int, actions=resubmit(,1)
table=0, priority=1, in_port=, actions=resubmit(,2)
table=0, priority=1, in_port=, actions=resubmit(,3)
table=0, priority=0, actions=drop
Table 1:
table=1, priority=0, dl_dst=00:00:00:00:00:00/01:00:00:00:00:00, actions=resubmit(,20)
table=1, priority=0, dl_dst=01:00:00:00:00:00/01:00:00:00:00:00, actions=resubmit(,21)
Table 2:
table=2, priority=1, tun_id=xxx, actions=mod_vlan_vid: xxx, resubmit(,10)
table=2, priority=0, actions=drop
Table 3:
table=3, priority=1, tun_id=xxx, actions=mod_vlan_vid: xxx, resubmit(,10)
table=3, priority=0, actions=drop
Table 10:
table=10, priority=1 actions=learn(table=20,hard_timeout=300,priority=1,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:0->NXM_OF_VLAN_TCI[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]),output:patch-int
Table 20:(由Table 10自学习触发流表项的生成)
table=20, priority=0, actions=resubmit(,21)
Table 21:
table=21, priority=1, dl_vlan=xxx, actions=strip_vlan, set_tunnel:xxx, output->[gre/vxlan ports]
table=21, priority=0, actions=drop
=====================Tables in br-tun =========================
对上述流表的语法进行两点介绍。
- 流表间的跳转并没有用标准OpenFlow规范中的指令GOTO_TABLE,而是使用了Nicira的扩展动作resubmit。
- Table 10中的(VLAN_ID,MAC)到(PORT_ID,TUNNEL_ID)映射关系的自学习使用了nicira扩展的寄存器机制,使得数据平面具备了相当的智能,能够大大减少控制信道的负担。OpenFlow 1.5中也提出了类似的机制。Table 10中完成自学习的流表项如下所示,主要分析里面的learn action。

– table=20,表示将学习到的流表放入Table 20
– NXM_OF_VLAN_TCI[0..11],记录当前数据包的VLAN_ID作为match中的VLAN_ID
– NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],记录当前数据包的源MAC地址作为match中的目的MAC地址
– load:0->NXM_OF_VLAN_TCI[],表示action中要去掉VLAN_ID
– load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],表示action中要封装隧道,隧道ID为当前隧道ID
– output:NXM_OF_IN_PORT[],表示action中的输出,输出端口为当前数据包的输入端口
可见,上述过程就是标准MAC自学习在隧道中的扩展,无非就是将(VLAN_ID,MAC)到PORT_ID的映射变为了(VLAN_ID,MAC)到(PORT_ID,TUNNEL_ID)的映射。这种自学习仍然要依赖于泛洪来完成,引入l2_population或者SDN控制器后可以避免掉泛洪。
(二)连接机制的优化
OVS上,连接机制的优化主要体现在l2_population机制,以及对DVR(Distributed Virtual Router,分布式L3-agent)的支持。
2.1)L2_population
虚拟机在通信前,会发送ARP请求去解析目的MAC与目的IP间的映射关系,这一过程需要发送二层的广播包。由(一)中的介绍可知,这会导致隧道上的泛洪,这显然是不能令人满意的。
传统网络中ARP依赖于广播泛洪的原因在于没有一个集中式的控制平面,而Neutron中的数据库存有所有虚拟机MAC地址与IP地址间的映射,可以说是一个天然原生的控制平面。因此有人提出了将该映射关系注入到OVS本地,在本地处理ARP广播,以避免隧道上的泛洪,这就是l2_population。
L2_population的实现并不复杂,就是在1介绍的流水线中增加一个ARP Table去处理ARP Request。ARP Table中会事先存好MAC与IP的映射关系,如果ARP Table中匹配ARP Request消息中的目的IP,则构造一个 ARP 响应包,从ARP Request的入端口返回给虚拟机。如果匹配失败,则跳转到 Table 21继续泛洪。上述过程如下图所示,之所以保留ARP Table到Table 21的跳转,主要是为了防止l2_population出现问题。

可以看到,Table 1的后续处理增加了ARP Table一个分支,所有的ARP Request都被发往了ARP Table(Table 1中匹配ARP Request的流表项的优先级高于单纯匹配广播的流表项的优先级)。ARP Table中的流表项match字段包括:以太网类型(ARP),VLAN ID和ARP请求中的目的IP地址,动作actions的伪代码如下:

其中:
- move:NXM_OF_ETH_SRC[]->NXM_OF_ETH_DST[],表示将ARP Request数据包的源MAC地址作为ARP Reply数据包的目的MAC地址
- mod_dl_src:%(mac)s,表示将ARP Request请求的目的虚拟机的MAC地址作为ARP Reply数据包的源MAC地址
- load:0x2->NXM_OF_ARP_OP[],表示将构造的ARP包的类型设置为ARP Reply
- move:NXM_NX_ARP_SHA[]->NXM_NX_ARP_THA[],表示将Request中的源MAC地址作为Reply中的目的MAC地址
- move:NXM_OF_ARP_SPA[]->NXM_OF_ARP_TPA[],表示将表示将Request中的源IP地址作为Reply中的目的IP地址
- load:%(mac)#x->NXM_NX_ARP_SHA[],表示将Request请求的目的虚拟机的MAC地址作为Reply中的源MAC地址
- load:%(ip)#x->NXM_OF_ARP_SPA[],表示将表示将Request请求的目的虚拟机的IP地址作为Reply中的源IP地址
- inport,表示将封装好ARP Reply从ARP Request的入端口送出,返回给源虚拟机
L2_population的工作就是这么简单,却可以大大减少不合意的隧道泛洪。其实dhcp也存在类似的问题,如果只在网络节点上放置dhcp-server,那么所有的DHCP DISCOVER消息都要靠隧道泛洪发送到网络节点上。当然,dhcp消息的数量和产生频率远远赶不上arp,问题也不会那么明显。
解决dhcp存在的上述问题,一种思路是在Table 21上专门写一条高优先级的dhcp流表项去匹配dhcp广播消息,并将所有的dhcp消息都封装送到网络节点的隧道。另外,也可以采用类似于l2_population的思路,从Table 1上专门写一条高优先级的dhcp流表项去匹配dhcp消息,这条流表项只需要将dhcp消息通过相应的端口转交给dhcp namespace即可。之所以用namespace实现,是因为Dhcp消息封装在应用层,OpenFlow流表无法直接支持dhcp消息的封装,因此这个活得由分布在计算节点上的dhcp namespace来完成。
第一种思路优点是实现简单,但是一旦网络节点发生单点故障,虚拟机便无法正常使用dhcp获取IP,不过kilo版本中已经有人在多个网络节点中实现了dhcp_loadbalance(https://blueprints.launchpad.net/neutron/+spec/dhcpservice-loadbalancing)。第二种思路实现复杂一些,但能够避免网络节点单点故障带来的问题,实现分布式dhcp。
2.2)DVR
上一小节简略地提到了分布式的dhcp,这个工作社区有人提过但是反响并不是很大,而分布式的路由(Distributed Virtual Routing)却很早就成为了社区的共识,并在Juno版本中给出了实现。
Neutron中Router用来实现同一租户不同网段的虚拟机间的通信,这属于东西向流量,具体可以分为两种:1. 同一个物理节点上不同网段内的虚机之间的通信;2. 不同物理节点上不同网段内的虚机之间的通信。Router还用来实现虚拟机与Internet间的流量,这属于南北向流量,具体也可分为两种:1. 虚拟机访问Internet的流量,通常需要经过SNAT处理;2. Internet访问虚拟机的流量,可能需要经过DNAT处理。
在Neutron较早的版本中,上述流量都需要通过经过网络节点上的Router来处理,一旦网络节点故障或者网络节点上的Router挂掉了,上述类型的流量也就都丢掉了。解决这一问题也有很多种思路:
- 一种是通过部署多个网络节点,在多个网络节点间做调度的,不过这种很难实现各个Router本身状态的一致性。
- 于是,就有了通过在Router间跑应用层面的VRRP来同步Router状态,这种方式是很不错的,VRRP协议也比较成熟。但是问题在于,大部分流量仍然需要“绕弯子”进行传输,如同一个物理节点上不同网段内的虚机之间的通信可能需要到另一个物理节点的Router上处理。
- 再于是,DVR就出现了,通过把Router分布在各个计算节点中,各类流量都可以得到最优的处理,也不会再有单点故障的问题了。
DVR在Juno版本提出,后续的版本中仍在不断地对其进行完善,DVR和其它高可用机制都体现了Neutron正在逐步具备在大规模生产环境中进行部署的能力。本小节将着重介绍DVR处理东西向流量的机制,最后简要给出DVR处理南北向流量的模型。
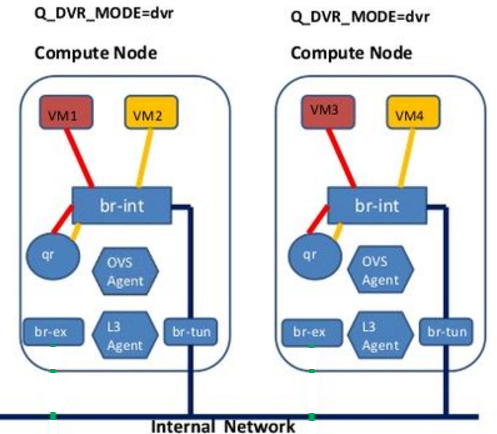
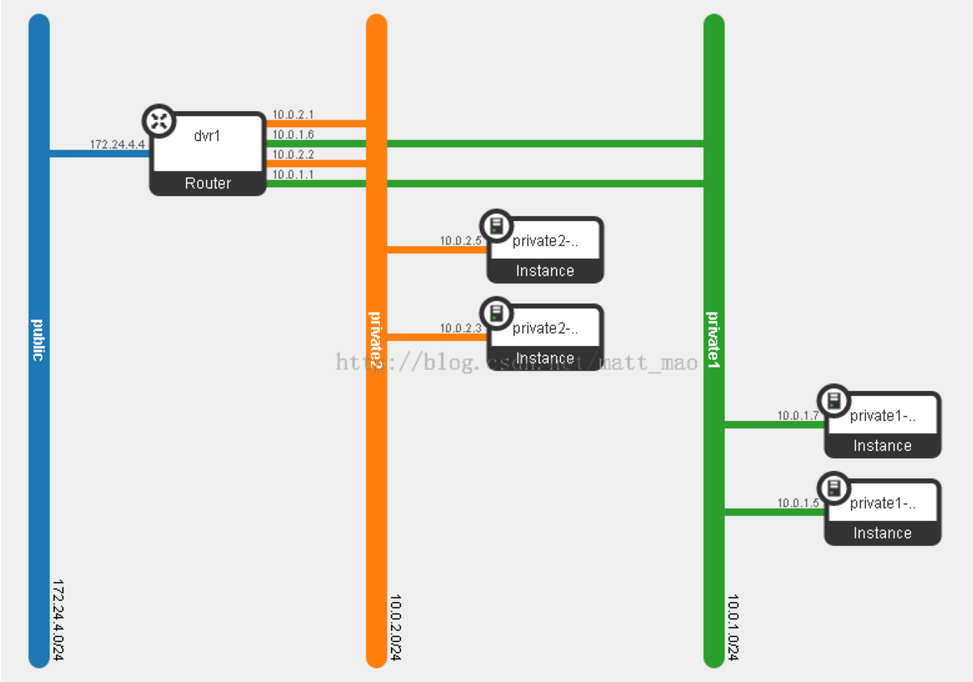
DVR对同一租户不同网段内虚拟机之间通信的处理,模型如下左图所示,Dashboard上看到的业务拓扑如下右图所示(另外请忽略IP地址),可以看到与DVR的使用对于租户来说是透明的。这一块具体的实现比较复杂,涉及到的东西比较多,需要依赖于计算节点上ovs-agent和L3-agent的相互配合。Ovs-agent负责在br-int和br-tun上增加一些DVR流表,而L3-agent则负责在本地完成路由的工作。我们主要对ovs上增加的DVR流表进行分析。
接下来的讲解发生在下图的场景中:某租户有红、绿两个网段,两台虚拟机vm1、vm2分属两个网段,分别位于计算节点CN1、CN2,租户拥有一个DVR路由器r1,分布在两个计算节点之上。假定vm1已经通过ARP获得了CN 1中r1在红色网段接口的MAC地址r1 red mac,现在vm1发起向vm2的ping request。
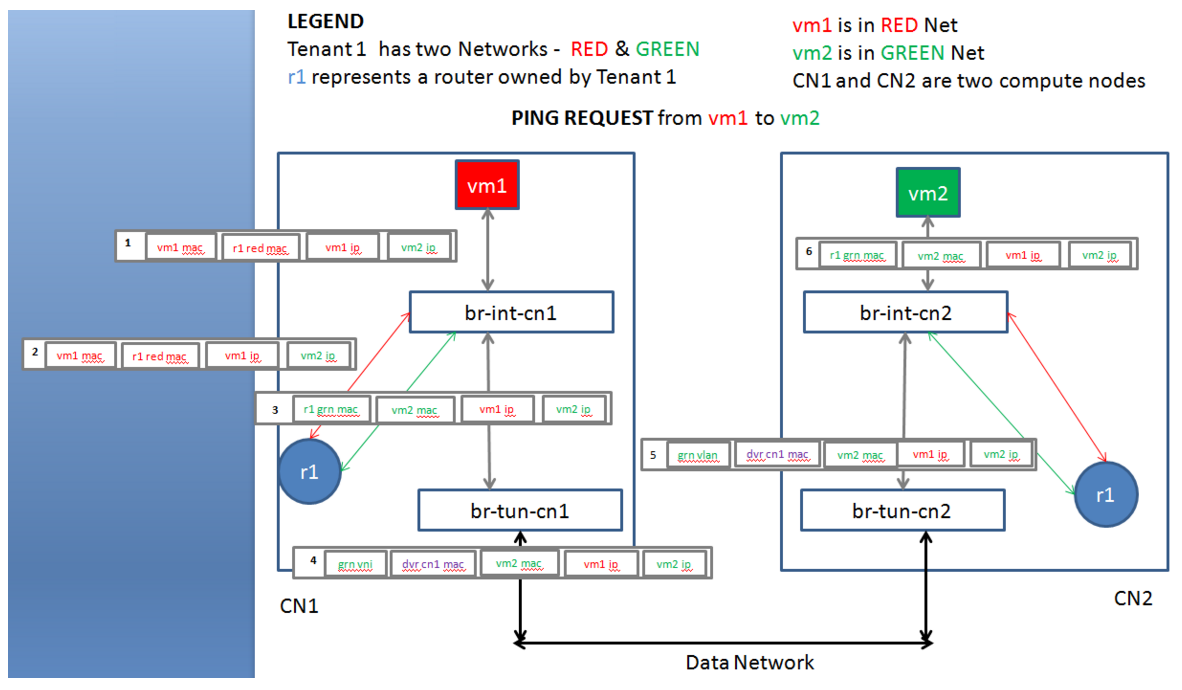
抛开流表的格式与下发的过程,先按照图中序号来看一看DVR流表下发后通信各个阶段的数据包特征。这里规定(源MAC,目的MAC,源IP,目的IP地址)为数据包的特征4元组。
1)vm1发出的ping包特征为(vm1 mac, r1 red mac, vm1 ip, vm2 ip),该数据包送至br-int-cn1。
2)br-int-cn1在之前ARP过程中学到了r1 red mac所在端口,将ping包直接转发给CN1中的r1。
3)r1进行路由,得知目的虚拟机连接在绿色网段上,而且r1中存有目的虚拟机的静态ARP表项,不需要进行ARP解析。于是CN1中的r1通过其绿色网段接口将ping包重新送回br-int-cn1。此时ping包特征为(r1 grn mac, vm2 mac, vm1 ip, vm2 ip),br-int-cn1还不知道vm2连在哪里,进行泛洪。
4)br-tun-cn1由br-int-cn1收到ping包,将源mac地址修改为全局唯一的dvr cn1 mac,并封装好隧道,标记绿色网段的TUNNEL_ID,直接送往CN2。此时ping包被封装在外层包头内,其特征为(dvr cn1 mac, vm2 mac, vm1 ip, vm2 ip)。
5)br-tun-cn2收到后去掉外层包头,打上绿色网段的本地VLAN标签,送给br-int-cn2,此时ping包特征仍为(dvr cn1 mac, vm2 mac, vm1 ip, vm2 ip)。
6)br-int-cn2识别出这是CN1经过绿色网段送过来的流量,于是将源mac地址改回r1 grn mac并剥掉VLAN标签。br-int-cn2还不知道vm2连在哪里,就将ping包泛洪。此时ping包特征为(r1 grn mac, vm2 mac, vm1 ip, vm2 ip)。
7)vm2收到ping request,回复ping echo,反向的通信过程和上述基本一致。
上述步骤给出了通信的外在特征,下面说明某些步骤内在的实现原理。
1)“r1中存有目的虚拟机的静态ARP表项”,是因为各个部署了DVR的计算节点中,l3-agent都事先从neutron数据库中获取了虚拟机的网络信息,直接注入到了r1中。这是为了防止r1跨隧道泛洪获取vm2的MAC地址(可以通过l2_population来实现)。
2)“将源mac地址修改为全局唯一的dvr cn1 mac”,是因为在所有计算节点上,r1位于相同网段的接口mac地址是一致的,即CN1上的r1 red/grn mac与CN2上的r1 red/grn mac一致。因此为了防止对端br-tun上的混乱, Neutron为每个部署了DVR的计算节点分配了全局唯一的dvr mac地址,br-tun在进行隧道传输前都需要进行源MAC地址的改写。
“并封装好隧道,标记绿色网段的TUNNEL_ID,直接送往CN2”,DVR要求开启l2_population事先学习(VLAN_ID,MAC)到(PORT_ID,TUNNEL_ID)的映射,以避免隧道上的泛洪。
3)br-tun-cn2解封装后,判断流量由dvr cn1送过来,不进行自学习,直接将流量送给br-int-cn2。
4)br-int-cn2中实现存有所有部署了DVR的计算节点的全局唯一的MAC地址,因而可以识别dvr cn1送过来的流量,完成源MAC地址的回写后进行转发。
根据上述描述,读者应该对整个过程有了一定的认识,下面来具体来看看流表的情况,由于CN 1和CN 2是对等的,我们只针对CN 1进行介绍,CN 2可类比得到。
先来看br-int-cn1上的流表情况。
前面的内容介绍过,在没开启DVR之前br-int-cn1上只有Table 0,而在开启DVR后,ovs-agent将为其增加DVR流表Table 1。Table 0在做正常的二层转发之前会做如下判断:入端口是否为与br-tun-cn1相连的patch-tun,以及源mac地址是否属于dvr mac地址(由于示例场景比较简单,图中示例流表只匹配了CN2的dvr-cn2-mac)。如果满足这两个条件,Table 0会将数据包送到Table 1中去处理。Table 1根据VLAN判断目的虚拟机所在网段,将源mac地址改为r1位于该网段接口的mac地址,剥掉VLAN并根据目的虚拟机的mac地址做出转发。下面给出各个流表项的标注,其中红色的为新增的DVR表项。
====================Tables in br-int-cn1=======================
#入端口是否为与br-tun-cn1相连的patch-tun?源mac地址是否属于dvr mac地址?是则转给Table 1
table=0, priority=2, in_port=patch-tun, dl_src=dvr-cn2-mac, actions=resubmit(,1)
table=0, priority=1, actions=NORMAL
#根据VLAN_ID判断目的虚拟机所在网段,将源mac地址改为r1位于该网段接口的mac地址,剥掉VLAN并根据目的虚拟机的mac地址做出转发
table=1, priority=4, dl_vlan=2, dl_dst=vm1-mac, actions=strip_vlan, mod_dl_src: r1-red-mac, output: vm1-port
#根据VLAN_ID判断目的虚拟机所在网段,将源mac地址改为r1位于该网段接口的mac地址,剥掉VLAN,并根据目的IP所在网段,向所有属于该网段的端口转发。
#正常情况下,数据包由上面priority=4的表项处理,该表项可能是为了防止上面表项未下发时流量能够送到目的虚拟机
table=1, priority=2, ip, dl_vlan=red, nw_dst=red-subnet , actions=strip_vlan, mod_dl_src:r1-red-mac, output:[vm1-port,…]
#未能匹配上的流量丢弃
table=1, priority=1, actions=drop
====================Tables in br-int-cn1=======================
再来看br-tun-cn1上的流表(注意,由于DVR流表Table 1、Table 9的插入,因此之前提及的Table号会随之改变)。
Table 0对数据包的来源进行判断,从与br-int相连的patch-int进入的数据包交给Table 1处理,从VxLAN端口(以VxLAN为例)进入的交给Table 4处理。Table 1判断数据包是否为发向r1的ARP,或者其他发给r1的二层帧,如果是则丢弃(为了保证虚拟机送到r1的数据包只在本地转发)。如果Table 1判断数据包是由r1发出来的,则将源mac地址改为CN1的dvr mac地址(为了避免对端br-tun上的混乱),然后送往Table 2。Table 2根据数据包目的MAC地址判断是否为单播,是则送往Table 20,否则送往Table 21。Table 20根据(VLAN_ID,MAC)到(PORT_ID,TUNNEL_ID)的映射关系将单播包送到特定的隧道,该映射关系可事先通过L2_populaiton学习到,也可以通过Table 10的触发学习到。Table 21将非单播包复制后送到所有隧道。进入Table4的数据包,首先判断TUNNE_ID是否合法,是则添加本地VLAN_ID并送往Table 9,否则丢弃。Table 9判断数据包源mac地址是否属于dvr mac地址(由于示例场景比较简单,图中示例流表只匹配了CN2的dvr-cn2-mac),如果是直接送给br-int-cn1处理,否则转给Table 10进行学习。Table 10记录数据包的VLAN_ID,MAC以及TUNNEL_ID,将(VLAN_ID,MAC)到(PORT_ID,TUNNEL_ID)的映射关系写入Table 20,然后从与br-int相连的patch-int送出。下面给出各个流表项的标注,其中红色的为新增的DVR表项。
====================Tables in br-tun-cn1=======================
Table 0(开启DVR之前就为Table 0):
table=0, priority=1, in_port=patch_int, actions=resubmit(,1)
table=0, priority=1, in_port=, actions=resubmit(,4)
table=0, priority=0, actions=drop
Table 1(新增DVR流表):
#判断数据包是否为发向r1的ARP,或者其他发给r1的二层帧,如果是则丢弃。保证了虚拟机送到r1的数据包只在本地转发
table=1, priority=4, arp, dl_vlan=red-vlan, arp_tpa=r1-red-ip, actions=drop
table=1, priority=4, arp, dl_vlan=grn-vlan, arp_tpa=r1-grn-ip, actions=drop
table=1, priority=2, dl_vlan=red-vlan, dl_dst=r1-red-mac, actions=drop
table=1, priority=2, dl_vlan=grn-vlan, dl_dst= r1-grn-mac, actions=drop
#判断数据包是否由r1发出来,是则将源mac地址改为CN1的dvr mac地址(为了避免对端br-tun上的混乱),然后送往Table 2
table=1, priority=1, dl_vlan=red-vlan, dl_src= r1-red-mac, actions=mod_dl_src:dvr-cn1-mac, resubmit(,2)
table=1, priority=1, dl_vlan=grn-vlan, dl_src= r1-grn-mac, actions=mod_dl_src: dvr-cn1-mac, resubmit(,2)
table=1, priority=0, actions=resubmit(,2)
Table 2(开启DVR之前为Table 1):
table=2, priority=0, dl_dst=00:00:00:00:00:00/01:00:00:00:00:00, actions=resubmit(,20)
table=2, priority=0, dl_dst=01:00:00:00:00:00/01:00:00:00:00:00, actions=resubmit(,21)
Table 4(开启DVR之前为Table 3):
table=4, priority=1, tun_id=red-vni, actions=mod_vlan_vid: red-vlan, resubmit(,9)
table=4, priority=1, tun_id=grn-vni, actions=mod_vlan_vid: grn-vlan, resubmit(,9)
table=4, priority=0, actions=drop
Table 9(新增DVR流表)
#判断源mac地址是否属于dvr mac地址,是则直接交给br-int-cn1,不再进行地址学习
table=9, priority=1, dl_src=dvr-cn2-mac, actions=output:patch-int
#其余提交 table 10 处理,进行地址学习
table=9, priority=0, actions=resubmit(,10)
Table 10(开启DVR之前就为Table 10)
table=10, priority=1 actions=learn(table=20,hard_timeout=300,priority=1,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:0->NXM_OF_VLAN_TCI[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]),output:patch-int
Table 20(开启DVR之前就为Table 20)
table=20, priority=0, dl_vlan=grn-vlan, dl_dst=vm2-mac, actions=strip_vlan, set_tunnel:grn-vni, output->cn2-vxlan-port
table=20, priority=0, dl_vlan=red-vlan, dl_dst=vm1-mac, actions=strip_vlan, set_tunnel:red-vni, output->cn1-vxlan-port
table=20, priority=0, actions=resubmit(,21)
Table 21(开启DVR之前就为Table 21)
table=21, priority=1, dl_vlan=red-vlan, actions=strip_vlan, set_tunnel:red-vni, output->[cn2-vxlan-port, networknode-vxlan-port]
table=21, priority=1, dl_vlan=grn-vlan, actions=strip_vlan, set_tunnel:grn-vni, output->[cn2-vxlan-port, networknode-vxlan-port]
table=21, priority=0, actions=drop
=====================Tables in br-tun-cn1======================
流表的逻辑跳转图如下所示(注意,某些Table的ID发生了变化,且未表示l2_population)。
以上的实例即为DVR对不同物理节点中同一租户不同网段虚拟机之间通信的处理,如果vm1和vm2位于同一物理节点中,则只有br-int会参与转发,br-tun将只起到一个作用——将虚拟机发给r1的包限制在节点本地。
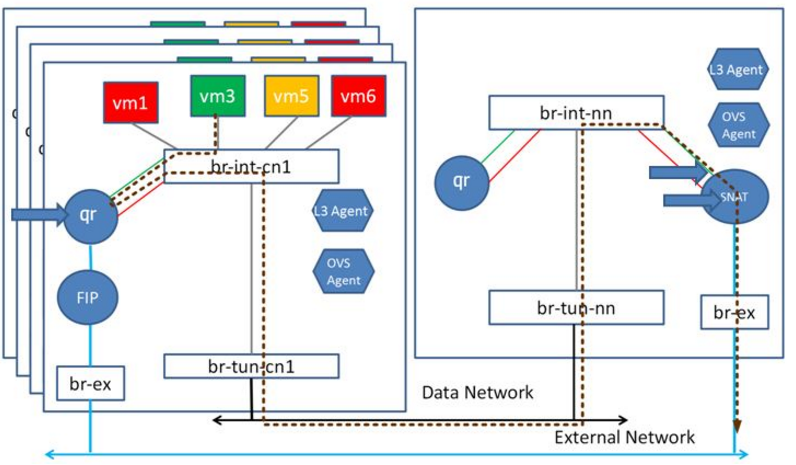
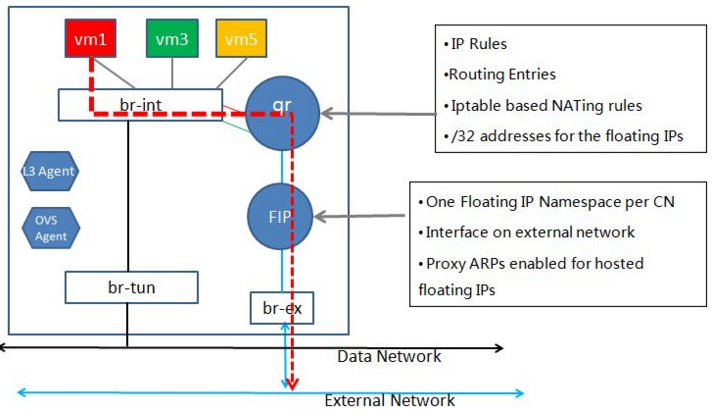
DVR对于南北向流量的处理有两种模型,第一种是SNAT在节点本地完成,第二种是SNAT仍需要到网络节点进行,两种模型分别示意如下。在节点本地进行SNAT则需要在计算节点的qr上为虚拟机分配浮动IP地址,而在网络节点完成SNAT比较节省公网IP资源,具体选择哪种模型,要视用户实际的业务需求而定。
讲到这里,对Neutron OVS上的流表分析就结束了。当然,Neutron的学问远远不止这些,看看目前社区已经完成的或正在进行的项目吧(https://wiki.openstack.org/wiki/Neutron)。下一节将简单地对kilo、liberty、mitaka版本中Neutron的blueprint进行整理,方便大家掌握社区的最新动态,将来能够共同学习。

作者简介:
张晨,2014/09-至今,北京邮电大学信息与通信工程学院未来网络理论与应用实验室(FNL实验室)攻读硕士研究生。
主要研究方向:SDN、虚拟化、数据中心
个人博客:sdnv.xyz
个人邮箱:zhangchen9211@126.com







